



Machine Learning Basics: Supervised vs. Unsupervised Learning
Demystify the core types of Machine Learning! Discover the fundamental differences between Supervised and Unsupervised Learning and how each empowers computers to learn from data. 🤖🧠

Machine Learning Basics: Supervised vs. Unsupervised Learning
Machine Learning (ML) is a captivating field that allows computers to learn from data without being explicitly programmed. It's the technology behind everything from personalized recommendations on Netflix to fraud detection systems in banks. But beneath the surface of this incredible capability are different approaches to how machines learn.
At Functioning Media, we believe in making complex topics accessible. For beginners diving into Data Science, understanding the fundamental distinction between Supervised Learning and Unsupervised Learning is your crucial first step. Let's explore these two core paradigms of how machines learn.
The Core Idea: Learning from Data 🤔
At its heart, Machine Learning is about enabling computers to identify patterns, make predictions, or take decisions based on data. The way we "teach" the machine these tasks largely defines whether it's supervised or unsupervised learning.
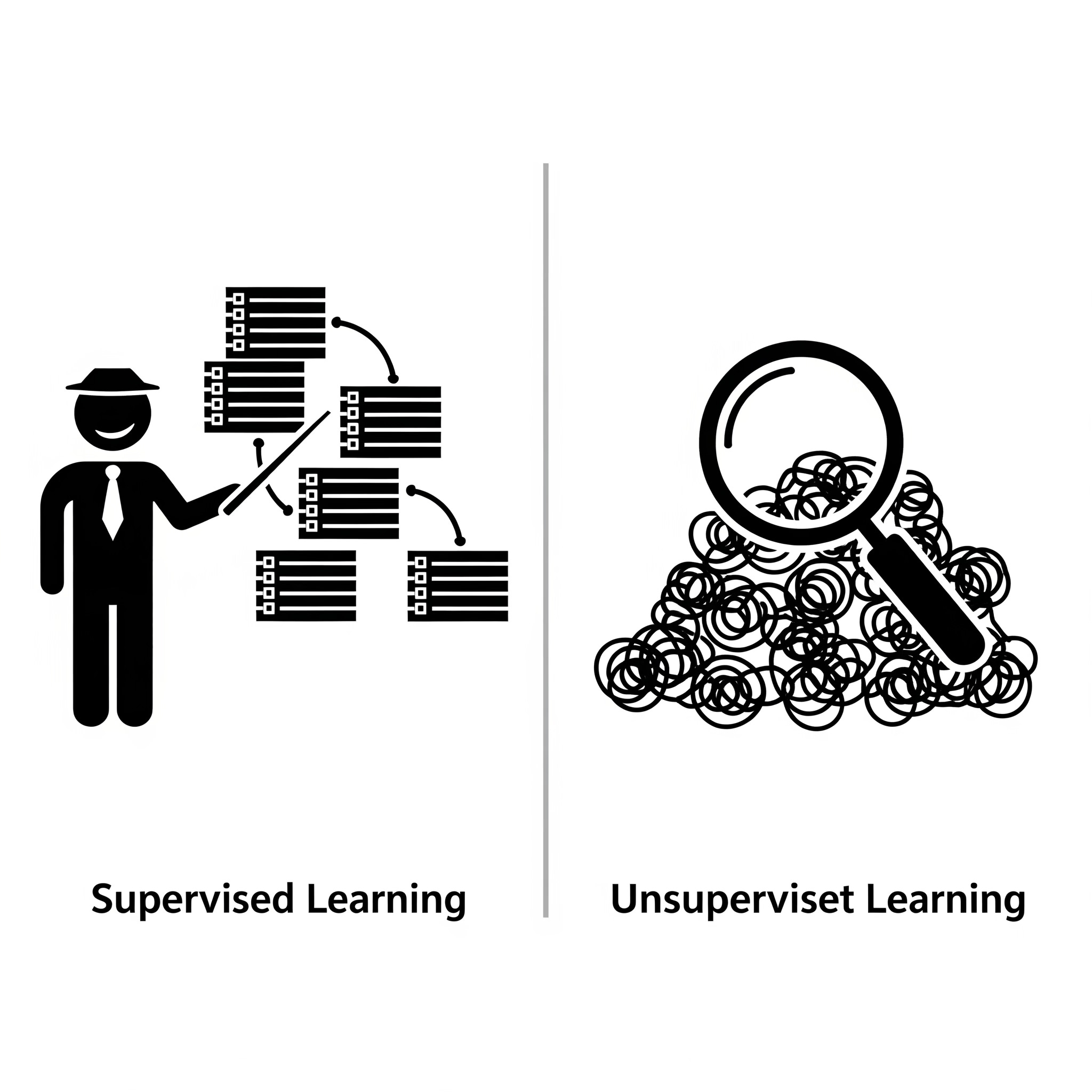
1. Supervised Learning: Learning with a Teacher 👨🏫
Imagine you're teaching a child to identify different animals. You show them a picture of a cat and tell them, "This is a cat." Then you show them a picture of a dog and say, "This is a dog." You're providing both the input (the picture) and the correct output (the animal's name).
Supervised Learning works in a similar way. It involves labeled data, meaning each piece of input data has a corresponding "correct answer" or "label." The machine learns by analyzing these input-output pairs and figuring out the rules that connect them. It then uses these learned rules to predict the output for new, unseen input data.
How it Works: The algorithm is "supervised" by the known outputs. It learns from its "mistakes" (differences between its prediction and the actual label) and adjusts its internal parameters until it can make accurate predictions.
Common Tasks:
Classification: Predicting a category or class (e.g., Is this email spam or not spam? Is this image a cat or a dog? Will a customer churn or not?). 🏷️
Regression: Predicting a continuous numerical value (e.g., What will the price of a house be? How many sales will we make next quarter? What will the temperature be tomorrow?). 📈
Examples: Spam detection, predicting house prices, image recognition, medical diagnosis.
2. Unsupervised Learning: Learning Without a Teacher 🕵️♀️
Now, imagine you give the same child a box full of mixed toys – blocks, cars, dolls – and tell them to organize them. You don't give them any instructions on how to group them. The child might group them by color, by type, or by size. They are finding patterns and structures on their own.
Unsupervised Learning operates on unlabeled data. There are no "correct answers" provided in the training data. Instead, the algorithm's goal is to discover hidden patterns, structures, or relationships within the data on its own. It's about finding the underlying order.
How it Works: The algorithm tries to understand the inherent structure of the data. It's not trying to predict a specific output, but rather to group similar data points or reduce data complexity.
Common Tasks:
Clustering: Grouping similar data points together into clusters (e.g., segmenting customers into different groups based on their purchasing behavior; identifying different types of news articles). 🤝
Dimensionality Reduction: Reducing the number of features or variables in a dataset while retaining as much important information as possible (e.g., simplifying complex genetic data for easier visualization). 📉
Association Rule Mining: Discovering rules that describe relationships between variables (e.g., "Customers who buy bread and milk also tend to buy eggs"). 🛒
Examples: Customer segmentation, anomaly detection (e.g., identifying unusual network activity), market basket analysis, data compression.
Supervised vs. Unsupervised Learning: A Quick Comparison
To summarize, the key difference between Supervised Learning and Unsupervised Learning boils down to the data they use and the goals they aim to achieve.
With Supervised Learning, you're working with labeled data – meaning you have both the input and the "correct" output. The machine learns by seeing these pairs and gets feedback on whether its predictions are right or wrong. Its main goal is to predict an output, like classifying an email as spam or predicting a house price. Think of problems like Classification and Regression.
On the other hand, Unsupervised Learning deals with unlabeled data. Here, the machine has no "teacher" and no correct answers to guide it. Instead, its objective is to discover hidden patterns, structures, or relationships within the data all on its own. It's about finding inherent order. Common problems solved by unsupervised learning include Clustering (grouping similar items) and Dimensionality Reduction (simplifying complex data).
Why This Distinction Matters:
Understanding whether a problem requires labeled or unlabeled data is the first critical step in choosing the right Machine Learning approach. At Functioning Media, our data science experts carefully analyze your data and business objectives to determine the most effective ML strategy, whether it's learning under supervision or discovering insights independently.
Visit functioningmedia.com and subscribe to the newsletter.
#MachineLearning #SupervisedLearning #UnsupervisedLearning #DataScience #AIBasics #MLForBeginners #DataAnalytics #AIExplained #LearnML #FunctioningMedia #Functioning #Media #Vishal #Rajput #VishalRajput